| На главную |
| 1.Как создают веб-страницы | |
| Как написать веб-страницу | |
| Обзор программ для просмотра и создания веб-страниц |
|
| Создание веб-страниц |
| 2.Основные средства языка HTML | |
| Самое главное на любой веб-странице - гиперссылки | |
| Как создать списки на веб-странице | |
| Создание таблиц |
| 3.Графика на веб-странице | |
| Графические форматы интернета |
|
| Графические элементы оформления веб-страниц |
|
| Графические маркеры | |
| Подготовка рисунков в программе Adobe Photoshop |
| 4.Оформление веб-страницы с использованием стилей | |
| Определение стилей в специальной таблице |
|
| Обзор других возможностий стилевых таблиц |
| 5.Использование звука на веб-странице |
|
| Маленькие хитрости |
| 6.Динамические веб-страницы на основе JavaScript |
|
| Как писать собственные функции | |
| Динамическое изменение внешнего вида страницы |
|
| Другие возможности языка JavaScript |
| 8.Размещение элементов на веб-странице с помощью таблиц |
|
| Управление расположением элементов на веб-страницы |
|
| Динамическое позиционирование слоев |
| 9.Дополнительные возможности формирования веб-страниц | |
| Пример использования элемента управления Tabular Data |
Дополнительные возможности формирования веб-страниц
В предыдущих главах мы рассмотрели основные приемы создания динамических веб-страниц, основанные на применении языка разметки HTML, таблиц стилей CSS и языка сценариев JavaScript. Собственно говоря, на этом можно было бы и завершить эту книгу. Девятая глава, которую вы сейчас читаете, является лишь небольшим дополнением к основному тексту. В ней мы коротко проиллюстрируем некоторые дополнительные возможности, которые имеются при создании веб-страниц. Такими возможностями являются, в частности, использование элементов управления Internet Explorer и применение простейших сценариев, исполняющихся на сервере.
Конечно, мы не будем описывать подробно ни то, ни другое — эта книга написана не про элементы управления и не про серверные сценарии. Однако краткая иллюстрация простейших возможностей нам представляется здесь вполне уместной, ибо может дать представлению читателю о некоторых других существующих web-технологиях.
Пример использования элемента управления Tabular Data
Использование элементов управления Internet Explorer имеет свои преимущества и недостатки. Преимущества заключаются в существенном расширении возможностей веб-страницы, а недостатки — в возможности просмотра только в Internet Explorer. Но поскольку этим броузером пользуется очень большое число посетителей WWW, применение элементов управления заслуживает внимания.
С помощью элементов управления можно, в частности, поместить на странице графику и анимированные фрагменты, записанные в виде простой последовательности команд. Пользователи Интернета, привыкшие, что для загрузки графики требуется заметное время, а для загрузки анимации — непомерное количество времени, будут приятно удивлены, увидев анимацию без утомительной загрузки.
Однако мы сейчас проиллюстрируем другую возможность — загрузку данных из базы. Возьмем, для примера, ту самую гипотетическую электронную библиотеку, титульную страницу которой мы создавали в главе 8. Предположим, что у нас есть архивные файлы с текстами книг, и нам нужно создать страницу выбора художественной литературы. Пусть нам нужно создать общий список книг и дать пользователю возможность выбора книг какого-либо автора по его имени.
Текстовая база данных
Для этого давайте создадим файл базы данных, в которой хранятся все сведения об имеющихся в библиотеке книгах. Для примера предположим, что у нас всего восемь книг. Файл базы данных будет представлять собой обычный текстовый файл (с расширением txt), в котором каждая строка является записью — данными об одной книге. Каждая запись состоит из нескольких полей: автор, название книги, размер файла и имя файла для загрузки. Чтобы не усложнять код, будем в этом месте просто ставить гиперссылку. Поля будем отделять друг от друга запятыми, например, так: Толстой,Анна Каренина,305,<А HREF="anna.zip">загрузить</А>
Как видите, заполнение базы данных вполне можно поручить любому человеку, умеющему использовать компьютер как пишущую машинку. (В принципе, можно избавить его и от необходимости писать страшную конструкцию <А HREF>.) В начале файла базы данных напишем заголовок каждого поля. Вот что у нас получится:
Author, Name, Size:INT, File
Дюма,Три мушкетера, 250, <A HREF="trim.zip">загрузить</А>
Дюма, Десять лет спустя,198, <А HREF="deslet.zip"> загрузить </А>
Дюма, Двадцать лет спустя,170, <А HREF="dvlet.zip"> загрузить </А>
Толстой, Война и мир,1045, <А HREF="vojna.rar"> загрузить </А>
Толстой, Анна Каренина, 305, <А HREF="anna.zip"> загрузить </А>
Достоевский, Идиот, 560, <А HREF="idiot.zip"> загрузить </А>
Достоевский,Преступление и наказание,710,<А HREF="prest.rar"> загрузить </А>
Достоевский,Двойник,432,<А HREF="doppel.zip"> загрузить </А>
Обратите внимание на то, что в первой строке мы написали просто заголовки полей. При этом можно было использовать любые слова — мы просто обозначили их так, чтобы было понятно, о чем речь. Поскольку в третьем поле каждой записи у нас будут храниться только числа (размер архивного файла книги в килобайтах), для экономии памяти мы можем указать, что это поле — числовое. Это делается с помощью ключевого слова INT.
Теперь давайте создадим саму веб-страницу. Сначала, как обычно, напишем заголовок и определим стиль вывода на экран:
<ТIТLЕ>Электронная библиотека</ТIТLЕ>
<STYLE> BODY {
background-color: #F4FFEF;
color: #182F1A;
font-family: sans-serif;
font-size: 120%;
}
</STYLE>
</HEAD>
<BODY>
<Н1>Художественная литература</Н1>
Элемент управления для работы с базой данных
Теперь, чтобы иметь возможность обращаться к базе данных, поместим на страницу элемент управления — он называется Tabular Data):
<OBJECT ID="hudlit"
CLASSID="clsid:333C7BC4-460F-llDO-BC04-0080C7055A83"
BORDER="0" WIDTH="0" HEIGHT="0">
<PARAM NAME="DataURL" VALUE="books.txt">
<PARAM NAME="UseHeader" VALUE="True">
</OBJECT>
Может показаться, что это выглядит «страшно», но не пугайтесь,
на самом деле все очень просто. Давайте разберемся. Элемент управления
помещается на страницу с помощью тега <OBJECT>. При этом атрибут
10= — это, как обычно, уникальное имя объекта. Столь необъятно выглядящий
атрибут CLASSID= является всего лишь идентификатором (проще говоря, номером)
соответствующей системной подпрограммы. Всякий раз, когда необходимо вставить
элемент управления Tabular Data, приходится вводить этот идентификационный
номер — clsid:333C7BC4-460F-11D0-BC04-0080C7055A83. У других элементов
управления другие номера, такие же длинные.
В первом из тегов <PARAM> мы связываем элемент управления с файлом базы данных. Здесь предполагается, что этот файл называется books.txt.
Второй тег <PARAM> указывает, что в базе данных первая строка используется как заголовочная. Это необходимо, поскольку далее мы будем обращаться к полям через их заголовки.
Динамическое формирование таблицы
Далее напишем таблицу, в каждой строке которой выводятся сведения об одной книге. Хитрость состоит в том, что в коде страницы мы укажем только одну строку таблицы. На самом же деле их будет создано столько, сколько записей будет выводиться на экран.
Чтобы связать таблицу с элементом управления, используем атрибут DATASRC=:
<TABLE DATASRC="#hudlit">
Обратите внимание на то, что мы указываем здесь не файл базы данных, а имя элемента управления, связанного с этим файлом. Теперь мы можем определить строку таблицы. В тех местах, куда нужно вставить значение какого-либо поля из базы данных, необходимо использовать атрибут DATAFLD=. Его удобно устанавливать в тегах <DIV> и <SPAN>:
<TR>
<TD><SPAN DATAFLD="Author"></SPAN>, «
<SPAN DATAFLD="Name"></SPAN>»,
<SPAN DATAFLD="Size"></SPAN> Кбайт.
<SPAN DATAFLD="File" DATAFORMATAS="html"></SPAN></TD>
</TR>
Посмотрите внимательно на этот код. Здесь определена одна строка
таблицы, состоящая из одной ячейки (можно было сделать и по-другому, например,
значение каждого поля поместить в свою ячейку). В этой ячейке последовательно
отображаются: значения первого поля (автор книги), запятая, открывающая
кавычка, значение второго поля (название книги), закрывающая кавычка,
запятая, значение третьего поля (размер файла), пробел, слово «кбайт»,
точка и значение четвертого поля (гиперссылка для загрузки текста книги).
Обратите внимание на то, что в последнем случае нам пришлось использовать
атрибут DATAFORMATAS='html', чтобы указать, что в базе данных содержатся
HTML-iervi. Если бы мы забыли применить этот атрибут, то в окне
броузера ссылка отобразилась бы в виде исходного кода. Собственно говоря,
нам осталось только поставить закрывающие теги:
</TABLE>
</BODY>
</HTML>
Все остальное
сделает элемент управления Tabular Data. Он «пройдется» по всем записям файла
базы данных, и для каждой из них автоматически создаст новую строку
таблицы.
Фильтрация таблицы
Теперь можно добавить возможность выбора автора из списка и затем отображать на экране книги только выбранного автора. Если в библиотеке очень много книг, такая возможность будет совсем не лишней! Сначала создадим список выбора с помощью тега <SELECT>, как объяснялось в главе 7:
Выберите автора:
<SELECT NAME="auth" onChange="auth() ">
<OPTION VALUE="">Bce
<OPTION VАLUE="Дюма">Дюма
<OPTION VALUE="Достоевский">Достоевский
<OPTION VАLUЕ="Толстой">Толстой
</SELECT>
Поскольку при выборе какого-либо из пунктов списка содержимое окна броузера должно изменяться, применим обработчик событий onChange (напомним, что он реагирует на изменения значения). Пусть он вызывает еще не написанную функцию auth(), которая будет выводить на экран книги только выбранного автора. Для облегчения написания этой функции мы продублировали названия пунктов списка в атрибуте VALUE= каждого из тегов <OPTION>.
Теперь
напишем эту функцию. Это проще, чем может показаться. Дело в том, что у нашего
элемента управления есть свойство Filter, значением которого может являться
строка типа название_поля=строка, то есть сравнение одного из полей с
заданной строкой. В данном случае это может быть, например:
Author=Дюма.
Поскольку имя автора у нас уже хранится как значение атрибута
VALUE=, мы можем написать так:
hudlit. Filter="Author="+document.
all.auth.value;
Кстати, в
качестве значения атрибута VALUE= первого элемента списка («Все») мы не зря
использовали пустую строку. Сравнение с ней в любом случае даст положительный
результат, поэтому она как бы отменяет фильтр. Теперь остается только
перерисовать изображения с помощью метода Reset:
hudlit.Reset();
Вот и все! Давайте теперь посмотрим, что у нас получилось.
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML> <HEAD> <ТITLЕ>Электронная библиoтeкa</TITLE> <STYLE> BODY { background-color: #F4FFEF; color: #182F1A; font-family: sans-serif; font-size: 120%; } </STYLE> <SCRIPT> function auth() { hudlit . Filter="Author="+document . all . auth . value ; hudlit. Reset () ; } </SCRIPT> </HEAD> <BODY> <Н1>Художественная литература</Н1> Выберите автора : <SELECT NAME="auth" onChange="auth () "> <OPTION VALUE="">Bce <OPTION VАLUЕ="Дюма">Дюма <OPTION VАLUЕ="Достоевский">Достоевский <OPTION VАLUЕ="Толстой">Толстой </SELECT> <BR><BR> <OBJECT ID = "hudlit" CLASSIC = "clsid:333C7BC4-460F-llD0-BC04-0080C7055A83" BORDER="0" WIDTH="0" HEIGHT="0"> <PARAM NAME = "DataURL" VALUE = "books. txt"> <PARAM NAME = "UseHeader" VALUE = "True"> </OBJECT> <TABLE DATASRC = "#hudlit"> <TR> <TD> <SPAN DATAFLD="Author"></SPAN>, « <SPAN DATAFLD="Name"> </SPAN>», <SPAN DATAFLD="Size"></SPAN> Кбайт. <SPAN DATAFLD="File" DATAFORMATAS="html"> </SPAN> </TD></TR></TABLE> </BODY> </HTML> |
Результат показан на рис. 9.1. На этом рисунке вы можете видеть
все названия книг, но если пользователь выберет из списка одного из авторов,
то в окне броузера отобразятся только книги выбранного автора.
Теперь можно
несколько усложнить задачу. Пусть пользователь имеет возможность не только
выбирать автора, но и вводить название книги
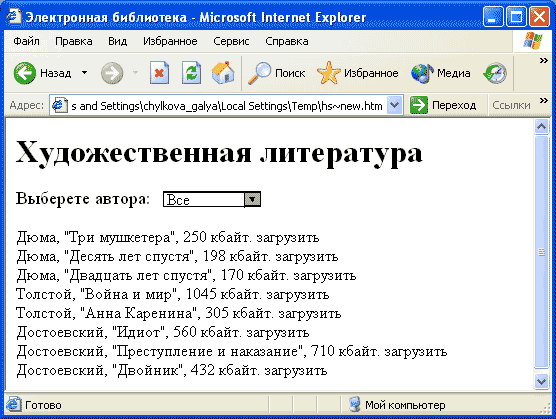
Рис. 9.1. Страница, на которой используются данные из базы
(мало ли, может быть, он и не помнит имя автора). Кроме
того, пусть у него будет возможность отсортировать список книг по имени
автора или по названию книги.
Поскольку мы
используем элемент управления Tabular Data, обе эти задачи решаются очень
просто. Чтобы пользователь мог сам ввести название нужной книги, создадим для
этого текстовое поле и кнопку Поиск рядом с ним:
<INPUT TYPE="text" NAME="book" SIZE="15" MAXLENGTH="25">
<INPUT TYPE="button" NAME="search" VАLUЕ="Поиск" onClick="bookname()">
Как видите,
кнопке Поиск мы назначили обработчик событий onClick. Теперь при нажатии этой
кнопки будет выполняться еще не написанная функция bookname(), которая должна
выбрать из «базы данных» только те записи, в которых присутствует введенное
пользователем название книги. Скорее всего, это будет одна запись, если,
конечно, в базе нет книг с одинаковыми названиями, как, например, «Записки
сумасшедшего» Гоголя и «Записки сумасшедшего» Толстого.
Собственно
говоря, эта функция очень похожа на предыдущую — нам ведь всего лишь нужно
применить свойство Filter, в условии которого сравнить значения поля Name
(название книги) со строкой, введенной пользователем:
hudlit.Filter="Name="+document.all.book.value; hudlit.Reset();
Правда, для наглядности хорошо бы при поиске введенной
пользователем книги вернуть список выбора автора в исходное состояние,
иначе может возникнуть следующая ситуация. Допустим, пользователь сначала
выбрал из списка одного автора (например, пункт Толстой) и увидел на экране
список имеющихся книг Толстого. Затем он решил поискать книгу под названием
«Тихий Дон» (которой в нашей базе данных пока нет). Он вводит в строку
поиска название книги и, естественно, не получает ничего в ответ. В этот
момент он смотрит на экран и видит, что у него в списке авторов выбран
Толстой. Тогда он начинает думать, что, наверное, компьютер искал «Тихий
Дон» Толстого, хотя на самом деле фильтр применялся ко всей базе. Пользователь
начинает раздражаться и нервничать.
Чтобы не возникало подобных недоумений, давайте просто при
поиске введенного пользователем названия книги автоматически выбирать
из списка авторов пункт Все. Для этого достаточно изменить свойство selectedIndex
списка выбора:
document.all.auth.selectedIndex=0 ;
Эту строку мы добавим в функцию bookname(). Аналогично можно
поступить и при поиске книг одного автора — на всякий случай очищать поле
ввода названия книги. Для этого добавим в функцию auth() следующую строку:
document.all.book.value="";
Сортировка таблицы
Теперь давайте осуществим сортировку списка книг. Добавим для
начала две кнопки — для сортировки по алфавиту, соответственно, авторов
и названий книг:
<INPUT TYPE="button" VАLUЕ="Сортировать
по автору" onClick="sort_auth()">
<INPUT TYPE="button" VАLUЕ="Сортировать
по названию" onClick="sort_name()">
Теперь напишем сами функции сортировки. Для этого нам подойдет чудесное свойство элемента управления Tabular Data, которое называется SortColumn. В качестве его значения нужно указать поле, значения которого нужно сортировать. Для сортировки по фамилиям авторов в данном случае следует указать поле Author, а для сортировки по названиям книг — поле Name. После этого нужно не забыть применить метод Reset(), чтобы заново «перерисовать» весь список:
function sort_auth() {
hudlit.SortColumn="Author";
hudlit.Reset();
}
function sort_name() {
hudlit.SortColumn="Name";
hudlit.Reset(); }
Кстати, применение метода сортировки может избавить от необходимости
заботиться о расположении записей в файле базы данных Например, в данном
случае при поступлении нового архива с текстом книги можно просто добавлять
запись о нем в конец файла. При загрузке файла можно сразу применить сортировку.
Кстати, это можно сделать и с помощью тега <PARAM>, который должен
быть внутри тега <OBJECT> элемента управления Tabular Data:
<PARAM NAME="SortColumn"
VALUE="Author">
В этом случае сразу после загрузки страницы записи будут отсортированы
по фамилиям авторов, независимо от того, в каком порядке они располагались
в файле базы данных.
Давайте посмотрим на текст получившейся страницы.
| <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML> <HEAD> <ТIТLЕ>Электронная библиoтeкa</TITLE> <STYLE> BODY { background-color: #F4FFEF; color: #182F1A; font-family: sans-serif; font-size: 120%; } </STYLE> <SCRIPT LANGUAGE=" JavaScript" TYPE="text/javascript"> <!-- function auth() { document . all . book . value="" ; hudlit . Filter="Author="+document . all . auth . value ; hudlit. Reset () ; } function bookname() { document . all . auth . selectedIndex=0; hudlit . Filter="Name="+document . all . book . value; hudlit. Reset () ; } function sort auth() { hudlit . SortColumn="Author"; hudlit. Reset () ; } function sort_name() { hudlit . SortColumn="Name" ; hudlit. Reset () ; } //--> </SCRIPT> </HEAD> <BODY> <Н1>Художественная литература</Н1> <INPUT TYPE="button" VАLUЕ="Сортировать по автору" onClick="sort_auth() "> <INPUT TYPE="button" VАLUЕ="Сортировать по названию" onClick="sort_name () "> <BR><BR> Выберите автора : <SELECT NAME="auth" onChange="auth () "> <OPT ION VALUE="">Bce <OPTION VАLUЕ="Дюма">Дюма <OPTION VАLUЕ="Достоевский">Достоевский <OPTION VАLUЕ="Толстой">Толстой </SELECT> <BR><BR> Или введите название книги: <INPUT TYPE="text" NAME="book" SIZE="15" MAXLENGTH="25"> <INPUT TYPE="button" NAME="search" VАLUЕ="Поиск" onClick="bookname () "> <BR><BR> <OBJECT ID="hudlit" CLASSID="clsid:333C7BC4-460F-llDO-BC04-0080C7055A83" BORDER="0" WIDTH="0" HEIGHT="0"> <PARAM NAME="DataURL" VALUE="books. txt"> <PARAM NAME="UseHeader" VALUE="True"> </OBJECT> <TABLE DATASRC="#hudlit"> <TR> <TD> <SPAN DATAFLD="Author"></SPAN>, « <SPAN DATAFLD="Name"></SPAN>», <SPAN DATAFLD="Size"> </SPAN> Кбайт. <SPAN DATAFLD="File" DATAFORMATAS="html"> </SPAN> </TD></TR> </TABLE> </BODY> </HTML> |
Результат
показан на рис. 9.2. Конечно, это очень простой пример, который хочется еще
улучшить. Например, перед поиском введенного пользователем названии книги хорошо
бы сначала удалить лишние пробелы и кавычки, а если введенное название не
найдено, то вывести сообщение об этом. Можно использовать файл базы данных для
построения нескольких различных страниц и т. д. Однако приведенный пример уже
дает некоторое представление о возможностях элемента Tabular Data. Читателям,
заинтересовавшимся использованием элементов управления в Internet Explorer,
можно рекомендовать обратиться к специальной литературе по этой
теме.
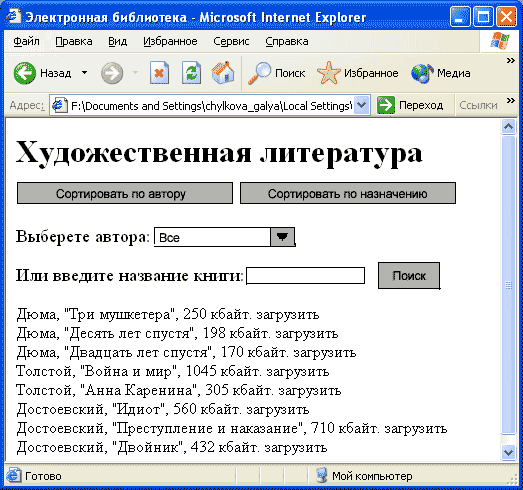
Рис. 9.2. Сортировка данных
9.2. Пример простейшего серверного сценария
Теперь приведем
простой пример сценария, который запускается прямо на сервере. Для чего это
нужно? Область применения серверных сценариев довольно широка. Подобные сценарии
могут, например, на ходу генерировать HTML-коц, и пересылать его
броузеру. Но мы рассмотрим пример, в котором сценарий будет принимать и
обрабатывать отправленную пользователем форму.
Помните, когда мы создавали страницу гипотетической фирмы «Лентяй»,
в ней был раздел «Книга отзывов» ? Там пользователю предлагалось ввести
свое имя в одно текстовое поле (с именем Name), а свое мнение — в другое
(многострочное) текстовое поле (с именем Opinion). Затем, после нажатия
кнопки Отправить заполненная форма отправлялась на сервер. Но что с ней
происходит там?
В качестве примера мы написали небольшой сценарий, который
принимает данные формы и создает текстовый файл, в который эти данные
записываются. Затем сценарий высылает пользователю сообщение об успешном
завершении работы.
Сценарий,
исполняемый на сервере, может быть написан на различных языках программирования
и использовать различные технологии. Например, он может использовать технологию
ASP (Active Server Pages) или специальную серверную редакцию языка
JavaScript. Однако чаще всего такие сценарии пишутся на языке Perl (и используют
технологию CGI — Common Gateway Interface). Мы сейчас не будем
рассказывать об этом подробно, а просто проиллюстрируем, каким может быть
простейший Perl-сценарий. Для облегчения восприятия давайте сначала напишем его
«построчно», а затем приведем полный текст.
Итак, в первой
строке мы должны указать местоположение интерпретатора языка Perl на сервере.
Его можно узнать у администратора сервера. Если сервер работает под управлением
Windows NT, а не UNIX или Linux, эта строка будет проигнорирована. Обычно она
выглядит так:
#! /usr/bin/perl
Теперь, чтобы мы могли легко считывать данные HTML -формы, надо написать еще одну строку:
require "cgi-lib.pl";
Эта строка подключает специальную библиотеку функций (cgi),
позволяющих, в частности, легко взаимодействовать с формами, отправленными
пользователем. Без этой библиотеки при написании сценария пришлось бы
сильно попотеть.
Поскольку мы будем отправлять пользователю подтверждение успешного
завершения работы, необходимо предварительно указать тип текста, который
сценарий будет посылать пользователю: print "Content-type: text/html\n\n";
Вообще говоря, все, что указано в операторе print, по умолчанию
будут отправлено на компьютер пользователя. Теперь нужно прочитать данные
формы, отправленной пользователем:
&ReadParse(*input);
Запись в файл
После этого нужно создать файл, в который записываются эти
данные. Этому файлу нужно дать какое-то имя. В принципе, это имя может
быть любым, но если мы просто укажем в сценарии конкретное имя, то при
обработке первого присланного отзыва все будет хорошо, но при обработке
второго отзыва новый файл заменит первый. Поэтому мы можем взять имя файла
из имени, введенного пользователем. Однако может случиться, что несколько
пользователей введут одинаковые имена. Что же делать?
Выйти из положения можно разными способами. Один из них заключается
в том, чтобы сгенерировать имя файла из имени, введенного пользователем,
и некого случайного числа. Таким образом, вероятность генерации двух одинаковых
имен файлов оказывается ничтожно малой.
Чтобы генерировать случайные числа, сначала необходимо инициализировать
их генератор:
srand($$^time);
Теперь можно сгенерировать само имя. Для удобства присвоим
его переменной $fname:
$fname=$input{"Name"}.int(rand(99999) ) ;
Имена переменных в языке Perl всегда начинаются со знака $.
Как вы можете заметить, мы здесь использовали новую переменную $fname,
не объявляя ее заранее. Но Perl — язык очень демократичный, здесь такие
вещи допускаются (точнее сказать — здесь допускается еще и не такое!).
С помощью функции rand(99999) мы генерируем случайное число в диапазоне
от 0 до 99 999, а затем отделяем от него целую часть с помощью функции
int. Знак «точка» означает конкатенацию, то есть присоединение
символьных строк друг к другу.
Хотя теперь вероятность совпадения двух имен файлов просто
ничтожно мала, все же на всякий случай перед созданием файла неплохо бы
проверить, не существует ли уже файл с тем же именем. Если он существует
(что почти невероятно), наш простенький сценарий просто выведет предупреждающее
сообщение для пользователя и завершит работу:
if (-e "$fname.txt") {
print ("Ошибка создания файла. Попробуйте еще раз!");
exit 0;
}
Как мы уже говорили, оператор print по умолчанию выводит
информацию на компьютер пользователя. На этом месте сценарий предлагает
пользователю попробовать отослать форму еще раз, так как теперь будет
сгенерировано другое имя файла.
Если же все в порядке, сценарий должен создать и открыть для
ввода данных файл с именем, хранящимся в переменной $fname и расширением
txt:
open (FILE,
">$fname.txt");
Теперь, чтобы иметь возможность записывать в этот файл какие-либо
данные, нужно, как говорят программисты, «перенаправить туда вывод» с
помощью оператора select:
select (FILE);
Это означает, что теперь, к примеру, оператор print будет выводить
данные не на компьютер пользователя, а в наш новый файл. Заметим время,
когда это произошло:
$tim=localtime();
Здесь мы получили
текущее время и дату с помощью функции localtime() и присвоили его переменной
$tim. Теперь давайте выведем сами данные:
print <<OTZYV
Отзыв пользователя $input{"Name"}
$input{"Opinion"}
Отзыв получен $tim
OTZYV
Кстати, это пример многострочного оператора print. Вместо открывающих
кавычек здесь использованы символы<<и идентификатор (какое-нибудь
имя следующего многострочного блока), а вместо закрывающих кавычек — только
имя многострочного блока. В результате мы можем просто набирать текст,
который должен быть выведен. В этот текст, однако, можно подставлять значения
переменных: в данном случае вместо $input{"Name"} будет выведено имя пользователя,
которое он ввел в поле формы с именем Name, вместо $input{"Opinion"} —
его мнение, введенное в многострочное текстовое поле Opinion. А вместо
переменной $tim будет выведено текущее время.
Теперь, когда все данные выведены, файл надо закрыть (только
при этом он окончательно сохраняется на диске). Это делается с помощью
оператора close:
lose(FILE);
Выдача сообщения пользователю
На этом миссия сценария завершается, но надо еще вывести
подтверждение успешного завершения работы, чтобы пользователь узнал об
этом. Это можно сделать с помощью оператора print, но прежде нужно перенаправить
вывод обратно пользователю:
select(STDOUT);
Слово STDOUT обозначает так называемый стандартный вывод,
куда данные выводятся по умолчанию. Теперь, наконец, можно послать
пользователю подтверждающее сообщение:
print "<Н1>Ваш отзыв был успешно отправлен на сервер
компании! </Н1>";
и завершить работу:
exit 0;
Хотя мы и рассмотрели написание этого сценария построчно, давайте все же теперь взглянем на него целиком:
#! /usr/bin/perl
require "cgi-lib.pl";
"Content-type: text/html\n\n";
&ReadParse(*input) ;
srand($$^time);
$fname=$input{"Name"}.int(rand(99999) ) ;
if (-e "$fname.txt") {
print "Ошибка создания файла. Попробуйте еще раз!";
exit 0;
}
open (FILE, ">$fname.txt");
select (FILE);
$tim=localtime();
print <<OTZYV
Отзыв пользователя $input{"Name"}
$input{"Opinion"}
Отзыв получен $tim
OTZYV
close(FILE);
select(STDOUT);
print "<Н1>Ваш отзыв был успешно отправлен на сервер компании! </H1>";
exit 0;
Конечно,
этот сценарий совершает довольно примитивную работу. Однако его рассмотрение
может дать некоторое представление о том, что за пределами HTML, CSS и
JavaScript открываются новые просторы Web-технологий. И мы надеемся, что после
прочтения этой книги наши читатели не просто научатся создавать динамические
веб-страницы, но и заинтересуются другими существующими
веб-технологиями.
И последний совет: чтобы научиться свободно обращаться с HTML/CSS/ JavaScript, как можно больше экспериментируйте самостоятельно! Начинать можно с изменений и «улучшений» приведенных в книге примеров, однако затем попробуйте создавать страницы самостоятельно «с нуля» или « почти с нуля ». А если вы увидите в WWW какую-либо интересную и красивую страницу, обязательно посмотрите на ее код, вникните в то, как она сделана. Такой опыт тоже очень полезен.
На этом мы, пожалуй, закончим наше путешествие в мир веб-технологий. Удачи вам, дорогой читатель, и хороших веб-страниц!